
In this post we will describe a process of adjusting raw data from multiple temperature sensors to remove offsets for accurate comparison when they are deployed as a set. This is not the same as calibration which often uses references with exact physical values to improve accuracy. However, normalization is a highly complementary way to improve precision which can be vital when you are studying systems that are driven primarily by gradients. Sous-vide cookers are portable so this procedure can be done in the field with a mix of sensors from different vendors. Sensors that are not inherently waterproof can be sealed inside food vacuum bags during the procedure.



Here we used this rig to normalize as set of Si7051’s reference sensors that will later be for calibrating the NTC thermistors on every Cave Pearl logger. We have accumulated quite a few of those Si’s over the years and it will be interesting to see if the older ones have drifted. But this 48 quart cooler also has enough volume to enable normalization of the temperature sensors inside the larger PVC housings on our older generation of loggers.
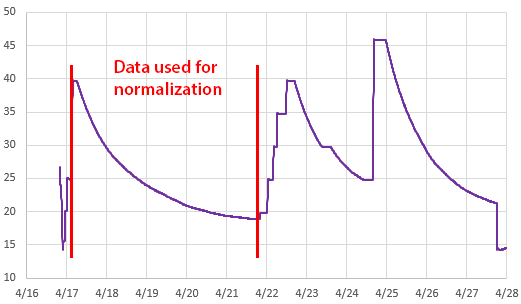
With the significant setup time, I created several ramps to provide some surplus data. Even with the thermal control of the Anova, I prefer to use the slow passive cooling curves whenever possible. With the circulator operating continuously the system took five days to cool from 40 to 20°C: slow enough to avoid any lag issues due to the housings or inconsistencies in the circulation.
Linear Y=Mx+B Normalization:
We have released many normalization tutorials over the years, but I will review the basic steps here for completeness. You start by drawing an average from your group of sensors. This will be the value each individual sensor gets adjusted to: (click to enlarge the images)
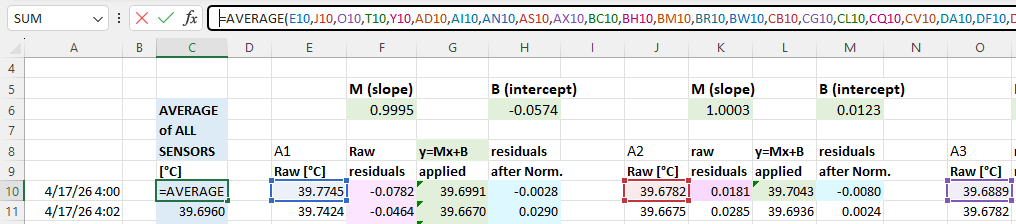
With that you calculate normalization constants using Excel’s slope & intercept functions with the columns of average & raw data for each sensor. Using these formulas lets you copy/paste the equations from one data set to the next which dramatically speeds up the process when you are working through many sensors. It also recalculates those constants if you add or delete information from the normalization set:
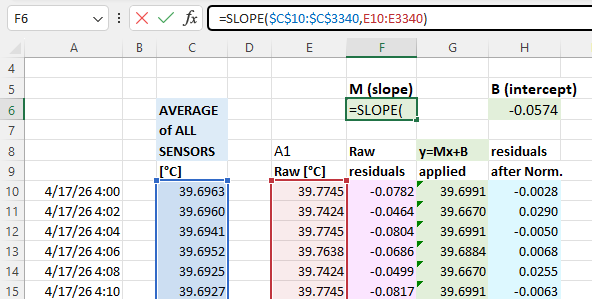
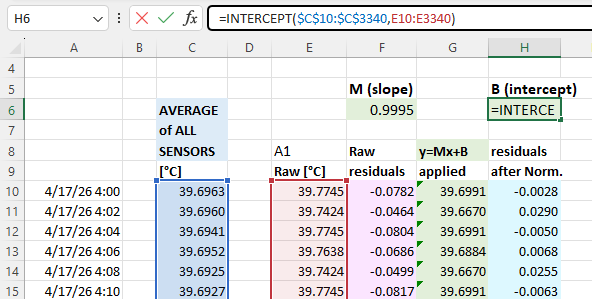
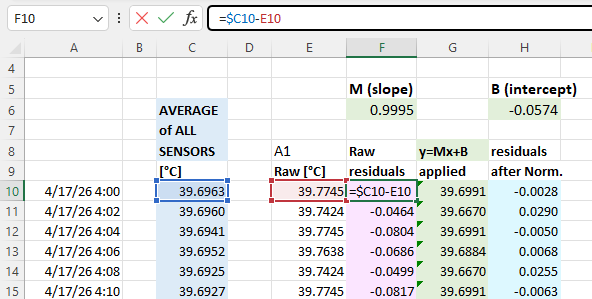
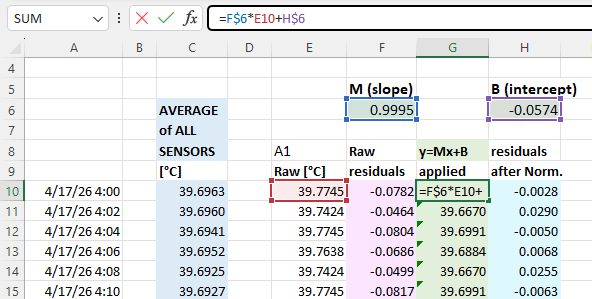
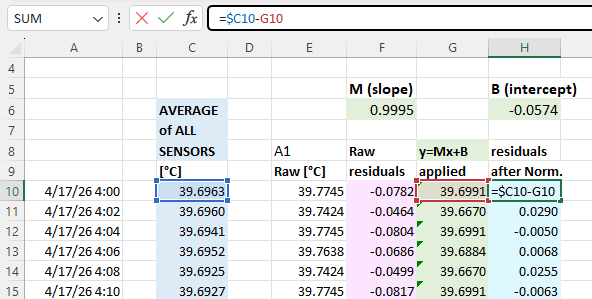
The next step is to calculate the difference (called residuals) between an individual sensors output and the average: you will do this both before and after the Y=Mx+B corrections have been applied to the temperature readings. These differences between the group average and a given sensor should be dramatically reduced by the adjustment:
Then create scatter plots of the pre & post normalization residuals so you can compare them side-by-side. The adjusted residuals should have very little slope and be equally distributed around ZERO:
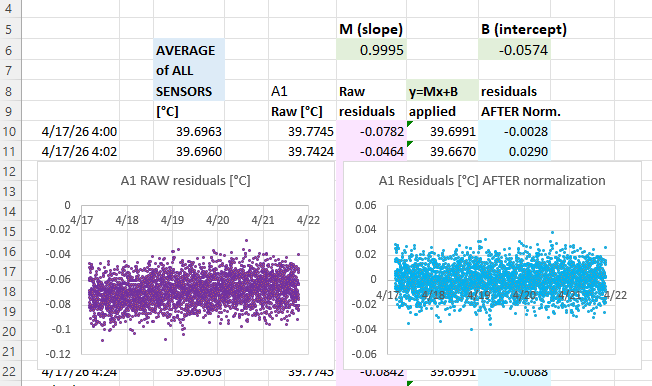
I should mention here how remarkable it was that this batch of sensors produced what I can only describe as textbook residuals with soft fuzzy distributions showing no observable patterns. Usually a batch of mixed sensors will show some structures in the residual plots – indicating that one (or more) of the sensors in the group has some kind of problem and might need to be removed from the group average. A failing sensor or connection issue should be your first suspect if you see step-changes in the residual plots when you know the physical system was changing slowly. If you can’t identify the misbehaving sensor to reject from a group, then you could normalize to the median rather than then average, as this tends to be more resilient to outliers.
A common source of problems during normalization is accidentally including data from a logger that has its timestamp offset from the rest of the group. This can be due to human error during setup but it also creeps in due to clock drift. In that case the overall pattern in the residuals plots will be a version of the same shapes you see in the raw sensor data. Its often useful to have some deliberately induced ‘sharp’ temperature changes in the raw data record to align the raw data records.
Sensors with heavy physical housings will tend to have excessive thermal lag compared to others a mixed normalization group. In that case you need to use the sous-vide cooker to create thermal plateaus that last long enough for all sensors to equalize – and only include that stabilized data in the normalization. The Anova itself takes a hour to settle near ambient, so you will need to leave the system for several hours at each temperature if you use the stepped plateau method. And it’s not unusual for a sensor inside an underwater housing to have more than an hour of thermal lag.
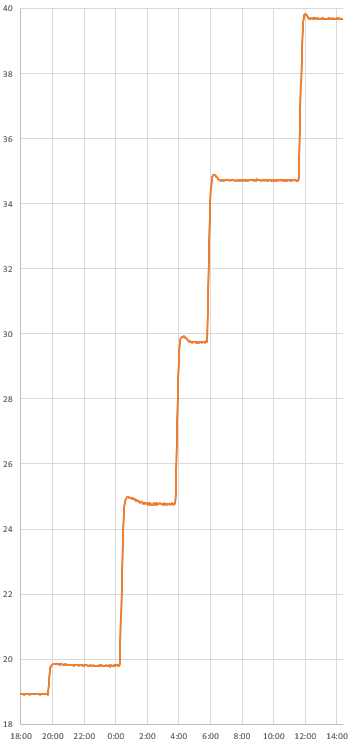
The result:
The Si7051 sensors we were using here have a maximum accuracy of ±0.1 °C in the human body temperature range of 35.8 °C to 41 °C, but this widens to ±0.25 °C between -40 and +125 °C. Even with this batch starting within that spec our normalization tightens the band to about 0.05°C :
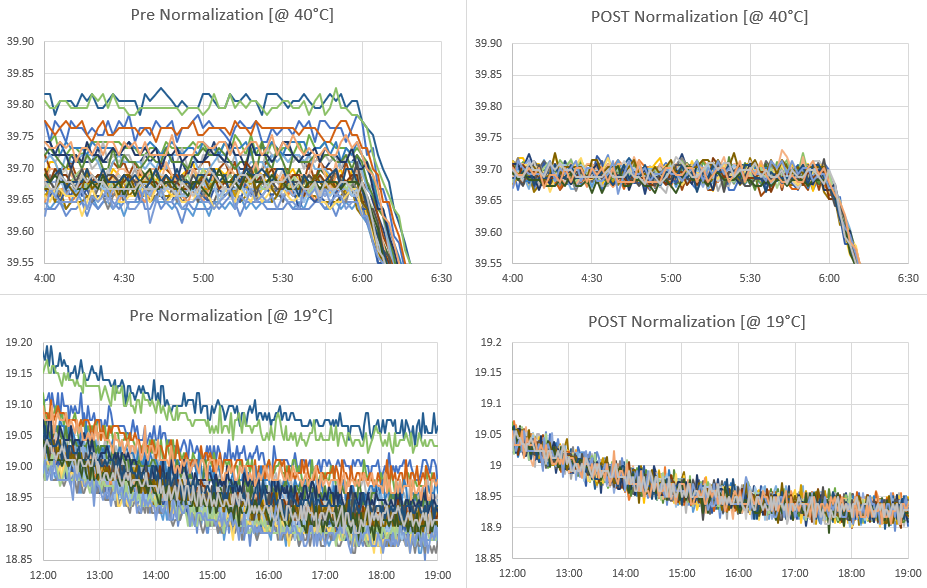
Like calibration, the raw data used to normalize sensors should cover the same range you expect to monitor in the field. There is no guarantee that fitting your sensors to an average will do anything to improve accuracy. However, sensors purchased from different vendors, at different times, tend to have randomly distributed offsets. In that case normalization also improves accuracy, but the only way to know if that has happened is to validate against some external reference. The method described here only corrects differences in Offset [with the B value] & Gain/Sensitivity [the M value]. Most temp sensors have a U-shaped error/noise distributions around their maximum accuracy point and if you see that pattern in the residual plots it means a linear correction is not sufficient and you might need to use a quadratic. Applying a linear correction to only one side of that curve (which I’ve done here) will increase errors on the other side of the distribution but as long as those amplified errors happen outside of the range of temperatures I intend to monitor then the trade-off is acceptable.
Comments:
After the normalization of the Si7051 reference sensors, data from that same run was also used to calibrate the NTC sensors on those new loggers. Instead of using the cooling curve, the NTC calibration is done with a couple of the flat plateaus and physical ice-points collected separately. Being able to graph the large group with data from the same circulation bath makes is easy to identify & fix any copy/paste errors made during the calculations.
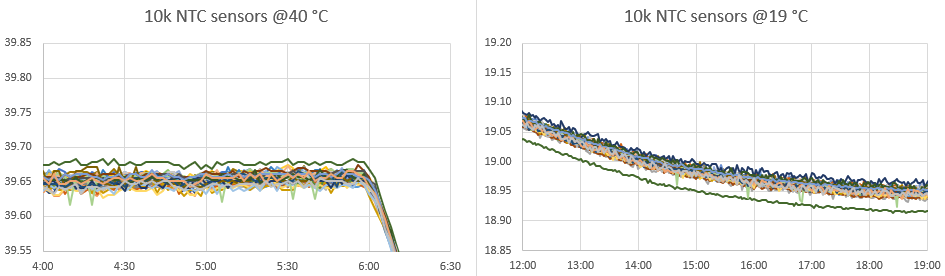
It’s interesting that the NTC’s clustered with an offset of ~0.05°C below the normalized Si7051s. I’m attributing this shift to using a data pair down at 0°C ( that was not in the normalization data set ) when calculating the Steinhart-Hart equation constants.
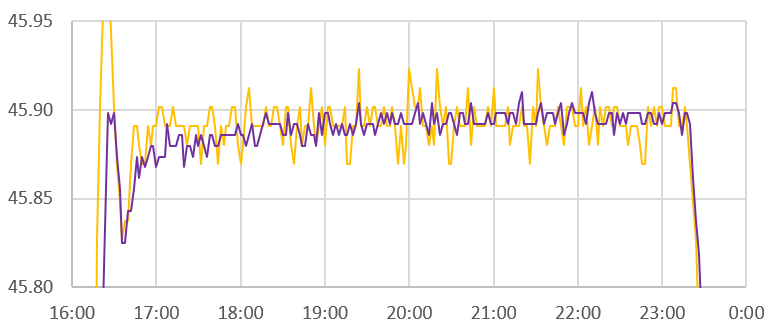
Out of forty DIY sensors, one (green) outlier above exhibited a slight nonlinearity problem that pushes it above the group at 40°C, but below the group at 19°C. Another exhibited a dramatic step-change behavior throughout the run and this logger will be rejected entirely from temperature sensing. Because our timing based method for reading NTCs treats the entire logger as a system, it will take more testing to see if this problem is with the physical sensor or with the ProMini module.
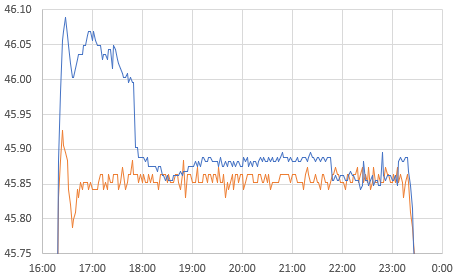
The higher resolution of the NTCs allowing us to look more closely at the Anova’s PID performance:
I suspect the 16 litre volume being driven here is near the practical limit of the little cookers capability, but the single wobble at the start of each plateau indicates a decent level of control. Especially considering the used cooker was $35 on eBay and the cooler was $10 at our local Goodwill. I’m still scratching my head about why the little Si7051 sensor modules read rising thermal spikes faster than the NTC but changes in the cooling direction stay aligned. I suspect this is due to direct conduction away from the NTC into the larger thermal mass of the ProMini board its attached to. Even with a thin housing that is IR transmissive, its not unusual to see a 15-20 minute lag in the NTC temperature readings relative to ambient.
References & Links:
Identifying Specific Problems Using Residual Plots
PID Controller – MATLAB (Guide) by Mike Deffenbaugh
PID Temperature Controllers: TUTCO Conductive
Anova’s Step-by-Step Guide to Building a Sous Vide Cooler
Considerations for water baths as calibration equipment
Guide on Secondary Thermometry: White et Al (2014)
Calibration of TAO array of moored buoys: NOAA
Normalization applied to a group of Pressure Sensors

This is again a great post to try to digest (as I run off for parts unknown), but I do have a slightly off-topic question. I know you use this (dataloggers) extensively in teaching; how do you teach this part of the process? How critical it is, when it can be relaxed, and when it can’t? I’ve found i can try to teach ‘best methods’ to my students, but often these are applied script-kiddie style with little understanding… which, predictably, reveals problems potentially late in the process. Has this been your experience? Or if not do you have any suggestions for getting around or past it?
Yep, that matches our experience. An introductory course is a spectacular success if you achieve -any- type of sensor of calibration as lab exercise just to deliver the concept. We’ve had success cross calibrating LDRs to light sensors, or calibrating the NTCs with our lunch box method [ https://thecavepearlproject.org/2024/04/20/a-practical-method-for-calibrating-ntc-thermistors/ ] So far the only students getting to the level of set normalization (or any kind of serious error analysis) are those doing independent projects with Dr. Beddows or those using the loggers for PHD level work. And yes, even then its often done only after their data has made them suspect there was some kind of problem rather than before hand when more testing would have prevented the issue. Two weeks of equipment pre-testing is vital for fieldwork success (even with commercial kit) however virtually no-one to date has been able to find that time before having to stuff everything into a suitcase. Our current solution to the lack of time problem is to simply deploy in multiples of 2-3 at every location so bad data can be spotted & rejected easily. Since it only takes an hour to build another logger (plus another hour for NTC cal) you can use that to get around up-front testing in a pinch. Given how often sensors go missing in the real world a minimum of three loggers are needed for any sampling spot anyway. But by far the biggest challenge is just getting students to realize that no equipment (no matter how much you paid for it!) should be trusted until you’ve personally done the work to verify it. The current generation are so used to technology like cell phones that “just works” without realizing the staggering number of clever people working hard to maintain that illusion.
With more thinking I remembered that over the years we’ve used several different methods to measure temperature on these loggers. The simplest is to record the temperature register on the DS3231 RTC. It’s low resolution and you will have an offset between the RTC and any reference sensor, but you can correct that with a linear from the same calibration dataset. We haven’t used that record since the early days of the project but if memory serves the RTC temp record had really low drift. Another way is to compare the crystal-driven system clock on the ProMini to the 328P watchdogs RC oscillator [https://thecavepearlproject.org/2019/02/25/no-parts-temperature-measurement-with-arduino-pro-mini-to-0-005c-or-better/] and a third temperature record can be had by comparing that 8MHz system clock to a one second alarm from the RTC: [https://thecavepearlproject.org/2018/02/03/measuring-temperature-with-two-clocks/] With four different ways to record temperature on a single logger, you should at least be able to spot when your primary temp sensor has gone AWOL even if you don’t have enough units for triple deployments. You could even normalize those records to each other(?) or create some kind of “composite” temperature record…